过去几个月,我们团队一直在为复杂工作流构建Skill——Bug 分诊、PR 治理、Sprint 报告——并通过 Claude Code 的插件市场和内部渠道分享。目标很直接:让团队和组织能够复用同样的问题解决能力。
但当我们真正尝试分发这些Skill时,采纳率很低。对于简单、轻量的Skill,分享没问题。但对于复杂的多工具工作流——那些解决最棘手问题的Skill——在作者机器上完美运行的东西,到了别人手里不是报错就是被闲置。我们怀疑这不是我们团队特有的问题。任何试图在组织内规模化Skill共享的团队,都可能撞上同样的墙。
所以我们问自己:为什么?
根因:依赖管理
在按照 Repo-as-Agent 模式构建团队 Agent 的过程中,我们认为找到了根因:依赖管理。
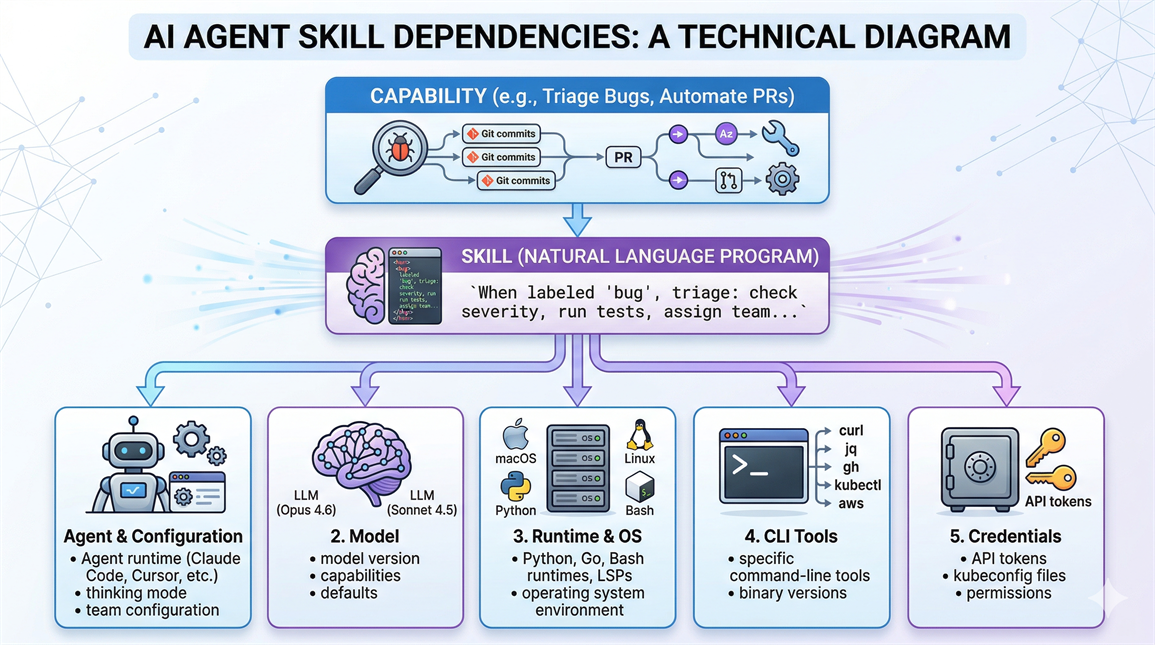
一个Skill不仅仅是一个 Markdown 文件。我们真正想分享的是解决特定问题的能力——但能力需要拆解成Skill:用自然语言写成的程序,规定 Agent 该做什么、按什么顺序、用什么工具。Skill有深浅之分:浅层通用的Skill(比如"执行 git rebase")传递起来毫不费力;深层的领域特定Skill——编排多步工作流、包含分支逻辑和隐含上下文——分享起来就困难得多,而偏偏是这些Skill在解决最棘手的问题。
和任何程序一样,Skill有依赖——一组隐式的前提条件,必须全部满足它才能跑起来。我们梳理了自己的依赖清单,归纳出五个类别。它们不是逐层堆叠的关系——任何一个单独就能导致失败:
- Agent 与配置 — Agent 运行时(Claude Code、Cursor、Cline)及其配置(思考模式、推理深度、Agent 团队等)。
- 模型 — 底层 LLM(Opus 4.6、Sonnet 4.5、Gemini、GPT 等)。
- 运行时与操作系统 — 语言运行时(Python、Go、Bash)、LSP 服务器,以及操作系统(macOS vs Linux)。
- CLI 工具 — Skill调用的外部二进制文件(curl、jq、gh、oc、kubectl、helm、aws 等)。
- 凭证 — API token、kubeconfig 文件、webhook URL、pull secret 及其关联权限。
每个类别中的问题
每个依赖类别都是一个潜在的失败点。分享一个Skill时,你其实在默认对方的环境在这五个维度上都和你一样。下面是各类别实际踩坑的情况:
Agent 与配置不匹配: 不同的 Agent 有不同的工具调用机制、权限模型和Skill格式。为 Claude Code 编写的Skill可能无法在 Cursor 中正确运行。即使在同一个 Agent 中,配置差异也会坑人:一个依赖子 Agent 委派的Skill,如果接收者没有启用 Agent 团队功能,就会静默失败。不同的思考深度设置会对相同的提示产生不同质量的推理。
模型差异: 模型在能力上有差异——不仅跨供应商(Claude vs Gemini vs GPT),同一供应商的不同层级(Opus vs Sonnet)也不同,甚至同一层级的不同版本也有区别。在 Opus 4.6 上可靠运行的Skill,在 Sonnet 4.5 上可能产生降级或错误的结果。在最近一次团队内的结对编程中,我们发现有些成员还在使用默认的 Sonnet 4.5 而不自知。这提醒我们,模型是一个容易被忽视的依赖——人们倾向于使用默认设置,很少检查它是否匹配Skill的设计要求。
运行时与操作系统分化: Shell 脚本在 macOS 和 Linux 上行为不同(GNU vs BSD coreutils、sed -i 语法、date 参数)。不同的 Python 或 Go 版本引入微妙的不兼容。缺少 LSP 服务器会降低代码智能能力。
CLI 工具缺失或不兼容: 我们的 Agent 依赖 16+ 个二进制文件。即使一个简单的 Jira Skill也需要 curl、jq、python3 和两个环境变量(见依赖矩阵)。一个缺失的二进制文件就会导致整个Skill失败。
权限不对称: 不同的工程师对不同的仓库有写权限、不同的集群访问级别、不同的管理员权限。一个用某人的 token 能正常工作的Skill,换了别人的可能静默失败——或者更糟,部分成功。
采纳失败的心理学
这些断裂点不只是技术问题——它们会改变人的行为。收到一个复杂Skill时,人不会只看它能省多少时间,还会掂量风险、稳定性和可控性。行为科学里有几个经典理论可以解释这种现象:
- 技术接受模型(Davis, 1989):采纳取决于"有没有用"和"好不好上手"。功能再强大,配置依赖搞得人头疼,就没人愿意用。
- 损失厌恶(Kahneman & Tversky, 1979):人对损失的感受大约是等量收益的 2 倍。工作流跑崩一次带来的挫败感,远大于它省下的时间。这也解释了现状偏见(Samuelson & Zeckhauser, 1988)——手动操作虽然慢,但至少不会炸。
- 自动化信任(Lee & See, 2004):信任建立在稳定的表现上。依赖没管好,表现就忽好忽坏,信任自然就没了。
- 算法厌恶(Dietvorst et al., 2015):自动化只要失败一次,人就会大幅降低使用意愿——哪怕它整体表现优于人类。一个因为少装了一个命令行工具就跑不起来的Skill,第一次失败基本就没有第二次机会了。
而且依赖对齐不可扩展。分享给 10 个人 → 对齐 10 个环境。更新Skill → 破坏全部 10 个。这就是"在我机器上能跑"的翻版——只不过现在那个程序是一个"Skill"。
我们的方案:容器 + 实时 Agent
我们回到了软件工程解决依赖管理的老办法:容器。
我们的 Dockerfile 打包了一切:3 个运行时、16+ 个 CLI 二进制文件、两个 LSP 服务器、GitHub App 认证脚本,以及一个标准化的 Linux 环境——彻底消除操作系统差异。相当于把依赖文档变成了可执行的镜像,文档更新了,镜像也跟着更新。
然后我们通过 KubeOpenCode 的实时服务器模式更进一步:从容器镜像部署一个实时 Agent,团队成员通过 Web UI 或 CLI 连接——无需本地配置。Agent 自带依赖预装、工具预配置、模型锁定、上下文预加载。
对于复杂工作流,分享 Agent 比分享Skill更有效。
待解的缺口:凭证
容器解决了五个依赖类别中的四个——Agent、模型、运行时和 CLI 工具。但凭证仍然是按人、按权限的——不同的工程师对不同的仓库有写权限、不同的集群访问级别、不同的管理员权限。
理想状态是:实时 Agent 有自己独立的身份,配上清晰的权限边界。但目前还没有成熟的方案,我们认为这是整个 Agentic 工程生态系统接下来要解决的问题。
结论
简单通用的Skill,分享起来没什么障碍。但复杂的、团队定制的工作流,光靠一个Skill文件远远不够——背后有五类隐式依赖(Agent、模型、运行时、CLI 工具、凭证),哪个没对齐都可能出问题,而出了问题就会丢失信任。我们用 Dockerfile 打包依赖、通过 KubeOpenCode 部署实时 Agent,解决了其中四类,让团队直接分享 Agent 而不是Skill文件。剩下的凭证管理——让 Agent 拥有独立身份和清晰的权限边界——是 Agentic 工程生态系统的下一个待解难题。